The App Engine platform manages the hardware and networking infrastructure required to run users application code. There are no servers to provision or manage
To deploy an application on App Engine, users just hand App Engine the application code and the App Engine service takes care of the rest
App Engine provides users with built-in services that many web applications need. No SQL databases, in-memory caching, load balancing, health checks, logging and a way to authenticate users
App Engine will scale a users application automatically in response to the amount of traffic it receives. So the user only pay for those resources they use
App Engine is especially suited for applications where the workload is highly variable or unpredictable like web applications and mobile backend
App Engine offers two environments: Standard and Flexible
The Standard environment is the simpler. It offers a simpler deployment experience and a fine-grained auto-scale
The Standard environment offers a free daily usage quota for the use of some services
With the Standard environment, low utilization applications might be able to run at no charge
Google provides App Engine software development kits in several languages, so that one can test their application locally before they upload it to the Google App Engine service
The App Engine SDKs provide simple commands for deployment
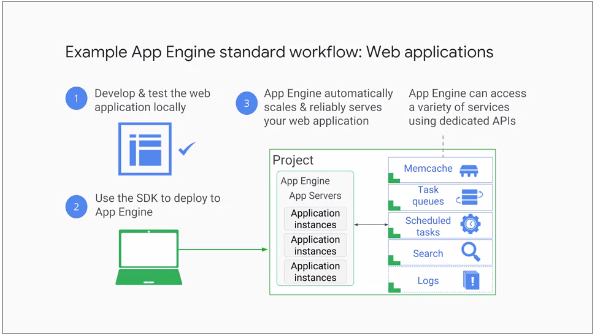
The following is the illustration of a typical App Engine workflow:
App Engine's term for the application executable binary is called the Runtime
In the Standard environment, you use a Runtime provided by Google
The Standard environment provides Runtimes for specific versions of Java, Python, PHP and Go. The Runtimes also include libraries that support App Engine APIs
If a user wants to code in another language, the Standard environment is not right choice and the user will want to consider the Flexible environmentZ
The Standard environment also enforces restrictions on the application code by making it run in a so-called Sandbox
A Sandbox is independent of the hardware, operating system, or physical location of the server it runs on. The Sandbox is one of the reasons why the Standard environment can scale and manage users application in a very fine-grained way
Sandboxes imposes some constraints. For example, an application code cannot write to the local file system. It will have to write to a database service instead if it needs to make data persistent. Also, all the requests the application receives has a 60-second timeout, and one can't install arbitrary third party software. If these constraints don't work for a user, they should choose the Flexible environment
Each App Engine application runs in a GCP project. App Engine automatically provisions server instances and scales and load balances them
In App Engine a user application can make calls to a variety of services using dedicated APIs. Here are a few examples: a NoSQL data store to make data persistent, caching of that data using Memcache, searching logging, user logging, and the ability to launch actions not triggered by direct user requests, like task queues and a task scheduler
Instead of the Sandbox, the Flexible environment lets a user specify the Container their application runs in
User application runs inside Docker containers on Google Compute Engine VMs and th App Engine manages these Compute Engine VMs. They are health checked, healed as necessary, and allows one to choose which geographical region they run in, and critical backward-compatible updates to their operating systems are automatically applied
The following is a side-by-side comparison of Standard and Flexible environments:
The Standard environment starts up instances of users application faster, but that users get less access to the infrastructure in which their application runs
The Flexible environment lets the users SSH into the virtual machines on which their application runs. It lets the users use local disk for scratch base, it lets the users install third-party software, and it lets their application make calls to the network without going through App Engine
The Standard environment's billing can drop to zero for the completely idle application
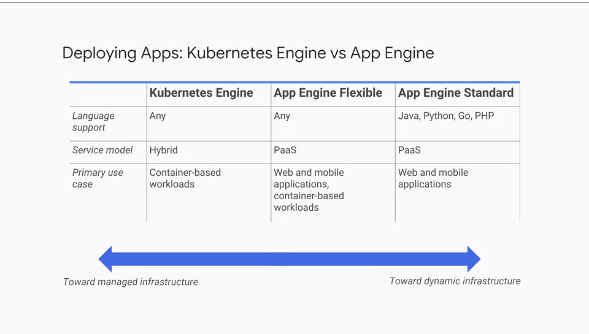
The following is a side-by-side comparison of App Engine and Kubernetes:
The Standard environment is for people who want the service to take maximum control of their application's deployment and scaling
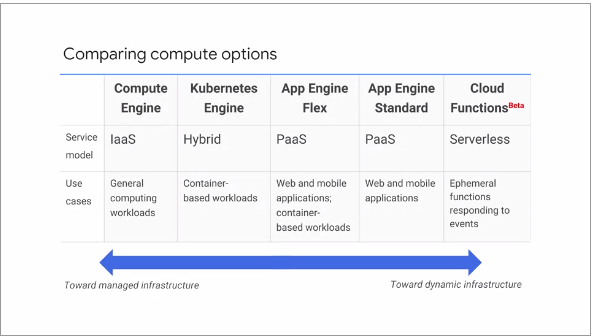
The following is a comparison of the various Compute options in GCP: