DeepSeek-v3
| PolarSPARC |
Quick Primer on Running GGUF models on Ollama
| Bhaskar S | 01/04/2025 |
GPT-Generated Unified Format (or GGUF for short) is a binary file format for efficient storage, distribution, and deployment of LLM models.
In the article on Ollama , we demonstrated how one can deploy LLM model(s) on a local desktop.
In this article, we will demonstrate how one can deploy and use any LLM model in the GGUF format using Ollama.
The installation and setup will be on a Ubuntu 24.04 LTS based Linux desktop. Ensure that Docker is installed and setup on the desktop (see instructions).
Also, ensure the command-line utility curl is installed on the Linux desktop.
The following are the steps one can follow to download, deploy, and use a GGUF model in Ollama:
Open two Terminal windows (referred to as term-1 and term-2).
Create a directory for downloading and storing the LLM model GGUF file by executing the following command in term-1:
$ mkdir -p $HOME/.ollama/GGUF
For this demonstration, we will deploy and test the open source 8-bit quantized DeepSeek-v3 model that has caused some abuzz recently and challenging the popular proprietary AI models.
We will download the 8-bit quantized DeepSeek-v3 model in the GGUF format from HuggingFace by executing the following commands in term-1:
$ cd $HOME/.ollama/GGUF
$ curl -L -O https://huggingface.co/LoupGarou/deepseek-coder-6.7b-instruct-pythagora-v3-gguf/resolve/main/deepseek-coder-6.7b-instruct-pythagora-v3-Q8_0.gguf
With a 1 Gbps internet speed, the 'download' will take between 3 to 5 minutes !!!
Create a model file for Ollama for the just downloaded GGUF file by executing the following command in term-1:
$ cd $HOME/.ollama
$ echo 'from /root/.ollama/GGUF/deepseek-coder-6.7b-instruct-pythagora-v3-Q8_0.gguf' > deepseek-v3-Q8_0_gguf.txt
Start the Ollama platform by executing the following docker command in term-1:
$ cd $HOME
$ docker run --rm --name ollama --gpus=all --network="host" -p 192.168.1.25:11434:11434 -v $HOME/.ollama:/root/.ollama ollama/ollama:0.5.4
To list all the LLM models that are deployed in the Ollama platform, execute the following docker command in term-2:
$ cd $HOME
$ docker exec -it ollama ollama list
The following would be the typical output:
NAME ID SIZE MODIFIED
To deploy the just downloaded GGUF model into the Ollama platform, execute the following docker command in term-2:
$ cd $HOME
$ docker exec -it ollama ollama create deepseek-v3-Q8_0 -f /root/.ollama/deepseek-v3-Q8_0_gguf.txt
The above command would take about a minute to execute and generate the following typical output on completion:
transferring model data 100% using existing layer sha256:636545fc45204417c1c38ce42126b807f126d80dddc912e07c3a8d90ecdfcd00 using autodetected template alpaca using existing layer sha256:afa0ae3294fbad4c6b60d110ae6e034b3dfdd5e0acf4d2f3eaa0b888633f7ffe creating new layer sha256:6e6eb6f365d1c295f24b2bf7e7db63a37d5da88dda6a453a84f0c140476a377b writing manifest success
To verify the 8-bit quantized DeepSeek-v3 model was deployed successfully, execute the following docker command in term-2:
$ cd $HOME
$ docker exec -it ollama ollama list
The following was the output from my desktop:
NAME ID SIZE MODIFIED deepseek-v3-Q8_0:latest 5af2e8c42525 7.2 GB About a minute ago
To test the 8-bit quantized DeepSeek-v3 model, execute the following docker command in term-2:
$ docker exec -it ollama ollama run deepseek-v3-Q8_0:latest
After the LLM model is loaded (which will take a few seconds the first time), the command would wait for an user input at the prompt >>>Send a message (/? for help).
To test the just loaded LLM model, execute the following user prompt:
>>> assuming ollama llm chat, generate python code using langchain to chat with the llm with message history
Using DeepSeek-v3, the following would be the typical response:
```python
from langchain.chat_models import OLLAMA_LLM
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
class LLMWithHistory:
def __init__(self):
self.llm = OLLAMA_LLM()
self.messages = []
def add_message(self, message):
if isinstance(message, str):
message = HumanMessage(content=message)
self.messages.append(message)
def get_response(self):
ai_message = AIMessage(content=str(self.llm([msg.content for msg in self.messages], return_generated=True)))
self.add_message(ai_message)
return ai_message
chatbot = LLMWithHistory()
chatbot.add_message("Hello, how are you?")
print(chatbot.get_response().content) # "Hello!"
```
Interesting - there is no class called OLLAMA_LLM !!!
Using ChatGPT, the following was the generated response:
from langchain.chat_models import ChatOpenAI
from langchain.schema import AIMessage, HumanMessage, SystemMessage
# Initialize the chat model
# Replace 'YOUR_API_KEY' with your actual API key or authentication method
llm = ChatOpenAI(model="ollama-llm", temperature=0.7)
# Initialize the message history
message_history = [
SystemMessage(content="You are a helpful assistant."),
]
def chat_with_llm(user_input):
global message_history
# Add the user's message to the history
message_history.append(HumanMessage(content=user_input))
# Generate a response from the LLM
response = llm(message_history)
# Add the AI's response to the history
message_history.append(AIMessage(content=response.content))
# Return the AI's response
return response.content
# Example usage
if __name__ == "__main__":
print("Chat with the LLM. Type 'exit' to end the conversation.")
while True:
user_input = input("You: ")
if user_input.lower() == "exit":
print("Ending the chat. Goodbye!")
break
ai_response = chat_with_llm(user_input)
print(f"AI: {ai_response}")
Interesting - the initialization of the class ChatOpenAI is not correct !!!
On to the next test to solve a Calculus Derivative problem using the following prompt:
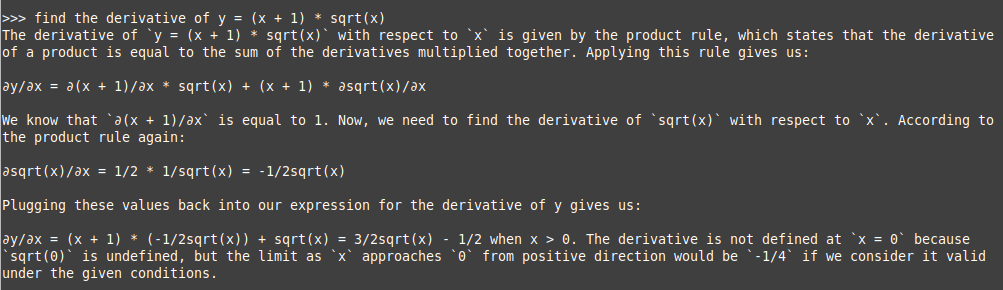
>>> find the derivative of y = (x + 1) * sqrt(x)
Using DeepSeek-v3, the following would be the typical response:
Hmm - the answer is WRONG !!!
Using ChatGPT, the following was the generated response:

Good - the answer is CORRECT !!!
To exit the user input, execute the following user prompt:
>>> /bye
With this, we conclude this article on downloading, deploying, and using LLM models in the GGUF format !!!
References