Figure.1
| PolarSPARC |
Quick Primer on LangChain
| Bhaskar S | *UPDATED*01/26/2025 |
Overview
LangChain is a popular, open-source, orchestration framework that provides a standardized abstraction for developing AI applications by hiding the complexities of working with the different Large Language models (or LLMs for short).
LangChain provides a collection of core component abstractions (or modular building blocks) that could be linked or "Chained" together to create complex AI workflows (or applications) to solve a plethora of tasks.
The following are the list of some of the important component modules from LangChain:
Models :: are standardized abstractions for interacting with AI models and are primarily of three types:
LLM Models are designed for interacting with the various LLMs, which take text input and generate text output
Chat Models are designed for interacting with the various LLMs using a chat style interaction in which the previous chat input is used as the context
Embedding Models are designed to convert an input text to a numerical embedding vector (see Word Embeddings )
Prompts :: are a set of instructions (or contextual inputs) provided by a user to guide the model to generate relevant response (or output). There are three types of standardized prompt abstractions:
Prompt Templates are reusable string templates with placeholders for contexts and instructions (or inputs), which can be dynamically set by a user at runtime, to generate specific prompt instructions for interacting with various LLMs
Example Selectors are a way to pass specific and relevant examples along with the input prompt to the LLMs in order to control the response (or output) from the LLMs
Output Parsers are responsible for taking the text response (or output) from the LLMs and transforming them to a specific structured format
Retrieval :: are related to how one can pass large amounts of user specific contextual data along with the instruction prompt to the LLMs. There are four types of standardized retrieval abstractions:
Document Loaders are useful for loading data documents from different sources, such as files (.txt, .pdf, .mp4, etc), from the web, or any other available sources.
Text Splitters are useful for splitting long documents into smaller semantically meaningful chunks so that they can be within the limits of the LLMs context window size
Vector Stores are used for storing vector embeddings of user specific documents and for later retrieval of similar documents (see Vector Database)
Retrievers are generic interfaces which are useful for querying embedded documents from various vectors sources including Vector Stores
Memory :: are used for preserving user prompts and responses from the LLMs so that they can be used for providing the context for future interactions with the LLMs
The intent of this article is NOT to be exhaustive, but a primer to get started quickly.
Installation and Setup
The installation and setup will be on a Ubuntu 24.04 LTS based Linux desktop. Ensure that Ollama is installed and setup on the desktop (see instructions).
In addition, ensure that the Python 3.x programming language as well as the Jupyter Notebook package is installed and setup on the desktop.
Assuming that the ip address on the Linux desktop is 192.168.1.25, start the Ollama platform by executing the following command in the terminal window:
$ docker run --rm --name ollama --network="host" -p 192.168.1.25:11434:11434 -v $HOME/.ollama:/root/.ollama ollama/ollama:0.5.7
For the LLM model, we will be using the recently released Microsoft Phi-4 model.
Open a new terminal window and execute the following docker command to download the LLM model:
$ docker exec -it ollama ollama run phi4
To install the necessary Python modules for this primer, execute the following command:
$ pip install chromadb dotenv langchain lanchain-core langchain-ollama lanchain-chroma langchain-community
This completes all the installation and setup for the LangChain hands-on demonstrations.
Hands-on with LangChain
Create a file called .env with the following environment variables defined:
LLM_TEMPERATURE=0.0 OLLAMA_MODEL='phi4:latest' OLLAMA_BASE_URL='http://192.168.1.25:11434' CHROMA_DB_DIR='/home/polarsparc/.chromadb' BOOKS_DATASET='./leadership_books.csv'
To load the environment variables and assign them to Python variable, execute the following code snippet:
from dotenv import load_dotenv, find_dotenv
import os
load_dotenv(find_dotenv())
llm_temperature = float(os.getenv('LLM_TEMPERATURE'))
ollama_model = os.getenv('OLLAMA_MODEL')
ollama_base_url = os.getenv('OLLAMA_BASE_URL')
chroma_db_dir = os.getenv('CHROMA_DB_DIR')
books_dataset = os.getenv('BOOKS_DATASET')
To initialize an instance of Ollama running the desired LLM model phi4:latest, execute the following code snippet:
from langchain_ollama import OllamaLLM ollama_llm = OllamaLLM(base_url=ollama_base_url, model=ollama_model, temperature=llm_temperature)
The temperature parameter in the above code is a value that is between 0.0 and 1.0. It determines whether the output from the LLM model should be more "creative" or be more "predictive". A higher value means more "creative" and a lower value means more "predictive".
The PromptTemplate class allows one to create an instance of an LLM prompt using a string template with placeholders (word surrounded by curly braces). To create an instance of a prompt from a string template, execute the following code snippet:
from langchain_core.prompts import PromptTemplate
template = """
Question: {question}
Answer: Summarize in less than {tokens} words.
"""
prompt = PromptTemplate.from_template(template=template)
Executing the above Python code generates no output.
To test the prompt instance with some test values for the placeholders, execute the following code snippet:
prompt.format(question='describe a leader', tokens=50)
Executing the above Python code generates the following typical output:
'\nQuestion: describe a leader\n\nAnswer: Summarize in less than 50 words.\n'
To create our first simple chain (using the pipe '|' operator) for sending the prompt to our LLM model, execute the following code snippet:
chain = prompt | ollama_llm
Executing the above Python code generates no output.
To run the just created simple chain by providing actual values for the placeholders in the prompt, execute the following code snippet:
print(chain.invoke({'question': 'describe a leader', 'tokens': 50}))
Executing the above Python code generates the following typical output:
A leader inspires and guides others with vision, integrity, and empathy. They empower teams through effective communication, foster collaboration, and adapt to challenges while maintaining focus on goals. A true leader motivates by example, encourages growth, and cultivates a positive environment for innovation and success.
In the above simple chain, the LLM model generated a unstructured text response (or output). There are situations when one would require a more structured response, like a list, or json, etc. This is where the Output Parsers come in handy. LangChain provides a collection of pre-built output parsers as follows:
CommaSeparatedListOutputParser
JsonOutputParser
PandasDataFrameOutputParser
XMLOutputParser
YamlOutputParser
For this demonstration, we will leverage the CommaSeparatedListOutputParser output parser. First, we will need to change the prompt a little bit. To create a new instance of a prompt from a string template that instructs the LLM to generate a list of items, execute the following code snippet:
from langchain_core.prompts import PromptTemplate
template2 = """
Generate a list of top five qualities about {subject}, with each feature using less than {tokens} words.
{format_instructions}
"""
prompt2 = PromptTemplate.from_template(template=template2)
Executing the above Python code generates no output.
To create a simple chain that sends the new prompt to our LLM model, execute the following code snippet:
chain2 = prompt2 | ollama_llm
Executing the above Python code generates no output.
To run the just created simple chain by providing actual values for the placeholders in the prompt, execute the following code snippet:
output = chain2.invoke({'subject': 'a leader', 'format_instructions': format_instructions, 'tokens': 5})
print(output)
Executing the above Python code generates the following typical output:
Inspiration, decisiveness, empathy, integrity, visionary
To create an instance of the output parser, execute the following code snippet:
from langchain.output_parsers import CommaSeparatedListOutputParser output_parser = CommaSeparatedListOutputParser()
Executing the above Python code generates no output.
To create a new chain that sends the response from our LLM model to the output parser, execute the following code snippet:
chain3 = prompt2 | ollama_llm | output_parser
Executing the above Python code generates no output.
To run the just created chain by providing actual values for the placeholders in the prompt, execute the following code snippet:
output2 = chain3.invoke({'subject': 'a leader', 'format_instructions': format_instructions, 'tokens': 5})
print(output2)
Executing the above Python code generates the following typical output:
['Inspiration', 'decisiveness', 'empathy', 'integrity', 'visionary']
Even though the LLM model(s) have been trained on vast amounts of data, one needs to provide an appropriate context to the LLM model(s) for better response (or output). To get better results, one can augment the LLM model's knowledge by providing additional context from external data sources, such as vector stores. This is where the Retrieval Augmented Generation (or RAG for short) comes into play.
To demonstrate the power of RAG, we will create a new instance of a prompt from a string template that instructs the LLM to generate a list of books on a given subject by executing the following code snippet:
from langchain_core.prompts import PromptTemplate
prompt3 = PromptTemplate.from_template(template='Generate a numbered list of top three books on {subject}')
Executing the above Python code generates no output.
To create a simple chain that sends the new prompt to our LLM model, execute the following code snippet:
chain4 = prompt3 | ollama_llm
Executing the above Python code generates no output.
To run the just created simple chain by providing actual values for the placeholders in the prompt, execute the following code snippet:
output3 = chain4.invoke({'subject': 'leadership'})
print(output3)
Executing the above Python code generates the following typical output:
Here are three highly regarded books on leadership:
1. **"Leaders Eat Last: Why Some Teams Pull Together and Others Don't" by Simon Sinek**
- This book explores the concept of creating environments where people feel safe, valued, and inspired to work together. Sinek delves into how leaders can foster trust and collaboration within their teams.
2. **"Dare to Lead: Brave Work. Tough Conversations. Whole Hearts." by Brene Brown**
- Brené Brown offers insights on leadership that emphasize vulnerability, courage, and empathy. She provides practical advice for leading with authenticity and building a culture of accountability and belonging.
3. **"The Five Dysfunctions of a Team: A Leadership Fable" by Patrick Lencioni**
- This book presents a fable about a team struggling to overcome common challenges that hinder performance. It outlines five key dysfunctions teams face and offers strategies for leaders to address these issues effectively.
These books provide diverse perspectives on leadership, focusing on trust-building, emotional intelligence, and team dynamics.
We will leverage the Chroma as the vector store for the RAG demo. In addition, we will handcraft as small dataset containing information on some popular leadership books.
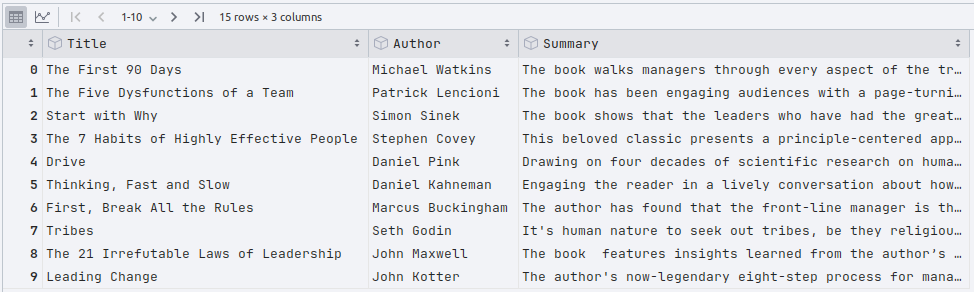
The following illustration depicts the truncated contents of the small leadership books dataset:
The pipe-separated leadership books dataset can be downloaded from HERE !!!
To load the pipe-separated leadership books dataset into a pandas dataframe, execute the following code snippet:
import pandas as pd books_df = pd.read_csv(books_dataset, sep='|') books_df
Executing the above Python code generates the typical output as shown in Figure.1 above.
The Document class allows one to encapsulate the textual content with metadata, which can be stored in a vector store for later searches.
To create a collection of documents from the rows of the pandas dataframe, execute the following code snippet:
from langchain_core.documents import Document
documents = []
for i in range(0, len(books_df)):
doc = Document(page_content=books_df.iloc[i]['Summary'], metadata={'Title': books_df.iloc[i]['Title'], 'Author': books_df.iloc[i]['Author']})
documents.append(doc)
documents
The following illustration depicts the partial collection of documents:

To store the documents (with textual content) into a vector store (as embeddings), we need to create an instance of vector embedding class corresponding to the LLM model. To create an instance of Ollama embedding, execute the following code snippet:
from langchain_ollama import OllamaEmbeddings ollama_embedding = OllamaEmbeddings(base_url=ollama_base_url, model=ollama_model)
Executing the above Python code generates no output.
To create an instance of the Chroma vector store with Ollama embedding, execute the following code snippet:
from langchain_chroma import Chroma vector_store = Chroma(embedding_function=ollama_embedding, persist_directory=chroma_db_dir)
Executing the above Python code generates no output.
To persist the collection of documents into the Chroma vector store, execute the following code snippet:
vector_store.add_documents(documents)
The following illustration depicts the list of document IDs stored in the vector store:

To create an instance of a vector store retriever that will return at most 2 similar documents, execute the following code snippet:
n_top = 2
retriever = vector_store.as_retriever(search_kwargs={'k': n_top})
Executing the above Python code generates no output.
To perform a query on similar documents from the Chroma vector store, execute the following code snippet:
query = 'a leaders guide to managing teams' similar_docs = retriever.invoke(query) similar_docs
The following illustration depicts the list of document IDs stored in the vector store:

To create a new prompt from a string template, with a placeholder for the contextual info from the vector store to instruct the LLM to generate a list of books by executing the following code snippet:
from langchain_core.prompts import PromptTemplate
template3 = """
Generate a numbered list of top three books on {subject} that are similar to the following:
{document}
"""
prompt4 = PromptTemplate.from_template(template=template3)
Executing the above Python code generates no output.
To create a simple chain that sends the new prompt to our LLM model, execute the following code snippet:
chain5 = prompt4 | ollama_llm
Executing the above Python code generates no output.
To run the just created simple chain by providing the contextual info from the vector store into the prompt, execute the following code snippet:
output4 = chain5.invoke({'subject': 'leadership', 'document': similar_docs[0]})
print(output4)
Executing the above Python code generates the following typical output:
Certainly! Here are three books on leadership that share similar themes to John Maxwell's "The 21 Irrefutable Laws of Leadership," focusing on insights from various fields:
1. **"Leaders Eat Last: Why Some Teams Pull Together and Others Don’t" by Simon Sinek**
- This book explores the importance of creating a safe environment for teams, drawing parallels between successful leadership in business and military settings.
2. **"Good to Great: Why Some Companies Make the Leap...and Others Don't" by Jim Collins**
- Collins examines what makes companies transition from being good to great, offering insights into leadership principles that can be applied across different industries.
3. **"The Five Dysfunctions of a Team: A Leadership Fable" by Patrick Lencioni**
- Through a fictional narrative, this book addresses common challenges in team dynamics and leadership, providing practical solutions applicable in various organizational contexts.
The reponse in Output.6 above is much more inline with what one would expect given the additional context.
Moving on to the example on memory, to initialize an instance of the chat model for Ollama running the LLM model vanilj/Phi-4:latest, execute the following code snippet:
from langchain_ollama import ChatOllama ollama_chat_llm = ChatOllama(model=ollama_model, temperature=0.0)
Executing the above Python code generates no output.
To initialize an instance of memory store that will preserve responses from the previous LLM model interaction(s), execute the following code snippet:
from langchain_core.chat_history import BaseChatMessageHistory, InMemoryChatMessageHistory
in_memory_store = {}
def get_chat_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in in_memory_store:
in_memory_store[session_id] = InMemoryChatMessageHistory()
return in_memory_store[session_id]
Executing the above Python code generates no output.
To create a new chat prompt template, with placeholders for the input as well as the chat history, execute the following code snippet:
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
prompt5 = ChatPromptTemplate.from_messages([
('system', 'Helpful AI assistant!'),
MessagesPlaceholder(variable_name='chat_history'),
('human', '{input}')
])
Executing the above Python code generates no output.
To create a simple chain that sends the user input to the chat LLM model, execute the following code snippet:
chain6 = prompt5 | ollama_chat_llm
Executing the above Python code generates no output.
To create a chain that sends the user request (along with the chat history) to the chat LLM model and captures the responses in the memory store, execute the following code snippet:
from langchain_core.runnables.history import RunnableWithMessageHistory chain6_with_history = RunnableWithMessageHistory(chain6, get_chat_history, input_messages_key='input', history_messages_key='chat_history')
Executing the above Python code generates no output.
To run the just created chain by providing an user input, execute the following code snippet:
config = {'configurable': {'session_id': 'langchain'}}
output5 = chain6_with_history.invoke({'input': 'Suggest only top 3 leadership quotes'}, config=config)
print(output5.content)
Executing the above Python code generates the following typical output:
Certainly! Here are three influential leadership quotes:
1. **"Leadership and learning are indispensable to each other."**
- *John F. Kennedy*
2. **"The best way to predict the future is to create it."**
- *Peter Drucker*
3. **"A leader is one who knows the way, goes the way, and shows the way."**
- *John C. Maxwell*
To demonstrate that the chain remembers and uses the previous chat response(s) as a context in the next interaction, execute the following code snippet:
output6 = chain6_with_history.invoke({'input': 'Quotes are not inspiring. try again'}, config=config)
print(output6.content)
Executing the above Python code generates the following typical output:
Certainly! Here are three more inspirational leadership quotes:
1. **"The only limit to our realization of tomorrow will be our doubts of today."**
- *Franklin D. Roosevelt*
2. **"Leadership is the capacity to translate vision into reality."**
- *Warren Bennis*
3. **"Great leaders are almost always great simplifiers, who can cut through argument, debate, and doubt to offer a solution everybody can understand."**
- *Ronald Reagan*
This concludes the hands-on demonstration of using the various LangChain components !!!
References