Figure.1
| PolarSPARC |
Quick Primer on LocalAI
| Bhaskar S | 09/28/2024 |
Overview
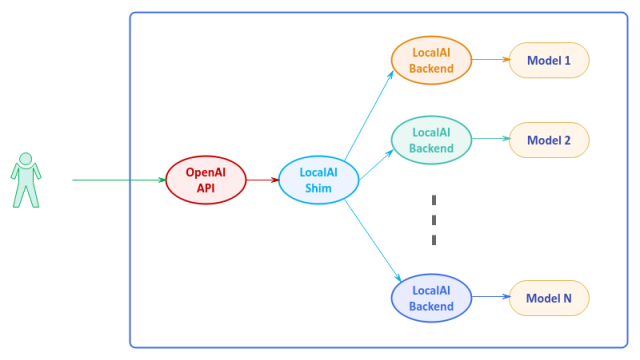
LocalAI is an open-source alternative to OpenAI that is written in golang and serves as an API shim for OpenAI allowing applications developed for OpenAI to seemlessly work with LocalAI.
LocalAI can easily run on either a consumer grade CPU or on a consumer grade GPU and can be used for performing various generative AI tasks such as text generation, text to audio generation, text to image generation, etc.
Behind the scenes LocalAI integrates with the various models (for the different tasks) via Backends, which are primarily gRPC servers that manage the models.
The following illustration depicts the high-level architecture of LocalAI:
For the hands-on demonstration of LocalAI, we will make use of the all-in-one Docker images (with aio in the image tag), which is pre-configured with a set of models and backends that fully enable all the features of LocalAI.
Installation and Setup
The installation and setup will be on a Ubuntu 22.04 LTS based Linux desktop. Ensure that Docker is installed and setup on the desktop (see instructions).
Also, ensure that the Python 3.x programming language as well as the Jupyter Notebook packages are installed. In addition, ensure the command-line utilities curl and jq are installed on the Linux desktop.
We will setup two required directories by executing the following command in a terminal window:
$ mkdir -p $HOME/.local_ai/audio $HOME/.local_ai/images $HOME/.local_ai/models
To download the latest version (v2.20.1 at the time of this article) of the docker image for LocalAI, execute the following command in a terminal window:
$ docker pull localai/localai:v2.20.1-aio-cpu
The following should be the typical output:
v2.20.1-aio-cpu: Pulling from localai/localai 857cc8cb19c0: Already exists 55fadcf27133: Pull complete 919319aaa5c1: Pull complete 11807c937ac8: Pull complete 9abe37b8dd91: Pull complete 0fa668082763: Pull complete 4f4fb700ef54: Pull complete 25d1bb267141: Pull complete b85112147d8a: Pull complete 42bc1bf73d44: Pull complete f08a77e602eb: Pull complete 309827c78ec0: Pull complete 5284a4495858: Pull complete 23368db5e6d0: Pull complete da4c6a8a825e: Pull complete d8ab882921d8: Pull complete 0523ef6554b8: Pull complete 311f15256acb: Pull complete 66f0e7f876f5: Pull complete d493b67858fd: Pull complete 20898ff942f0: Pull complete Digest: sha256:e1400072b5e3ec42fb504faafadcc4aa20a696c3f30b8edb9b923532942965b9 Status: Downloaded newer image for localai/localai:v2.20.1-aio-cpu docker.io/localai/localai:v2.20.1-aio-cpu
Most of the pre-trained LLM models are distributed in a binary file format called GPT Generated Unified Format (or GGUF for short).
Next, we will download the popular Microsoft Phi-3 Mini pre-trained LLM model as a gguf file by executing the following command:
$ curl -L https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf/resolve/main/Phi-3-mini-4k-instruct-q4.gguf --output $HOME/.local_ai/models/Phi-3-mini-4k-instruct-q4.gguf
The download will take a bit of a time and the following should be the typical output:
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1163 100 1163 0 0 11915 0 --:--:-- --:--:-- --:--:-- 11989
100 2282M 100 2282M 0 0 56.3M 0 0:00:40 0:00:40 --:--:-- 61.2M
To install the necessary Python packages, execute the following command:
$ pip install openai
This completes all the system installation and setup for the LocalAI hands-on demonstration.
Hands-on with LocalAI
Assuming that the ip address of the desktop is 192.168.1.25, start the LocalAI platform by executing the following command in a new terminal window:
$ docker run --rm --name local-ai -u $(id -u $USER):$(id -g $USER) --add-host=host.docker.internal:host-gateway --network="host" -p 192.168.1.25:8080:8080 -v $HOME/.local_ai/models:/build/models -v $HOME/.local_ai/images:/tmp/generated/images -v $HOME/.local_ai/audio:/tmp/generated/audio localai/localai:v2.20.1-aio-cpu
This will take a little bit of time and in the end the following would be the typical trimmed output:
[... SNIP ...] ===> LocalAI All-in-One (AIO) container starting... [... SNIP ...] 12:13PM INF core/startup process completed! 12:13PM INF LocalAI API is listening! Please connect to the endpoint for API documentation. endpoint=http://0.0.0.0:8080 12:14PM INF Success ip=127.0.0.1 latency="44.42µs" method=GET status=200 url=/readyz
Note that aio docker image will download the needed models on the first run if not already present and store those in /build/models volume of the container.
To test the local API endpoint, open a new terminal window and execute the following command to list all enabled AI models that are hosted on the running LocalAI platform:
$ curl -s http://192.168.1.25:8080/v1/models | jq
The following should be the typical output:
{
"object": "list",
"data": [
{
"id": "gpt-4",
"object": "model"
},
{
"id": "gpt-4-vision-preview",
"object": "model"
},
{
"id": "jina-reranker-v1-base-en",
"object": "model"
},
{
"id": "stablediffusion",
"object": "model"
},
{
"id": "text-embedding-ada-002",
"object": "model"
},
{
"id": "tts-1",
"object": "model"
},
{
"id": "whisper-1",
"object": "model"
},
{
"id": "Phi-3-mini-4k-instruct-q4.gguf",
"object": "model"
},
{
"id": "bakllava-mmproj.gguf",
"object": "model"
}
]
}
Next, to send a user text to the default text-embedding-ada-002 model for an embedding response, execute the following command:
$ curl -s http://192.168.1.25:8080/v1/embeddings -X POST -H "Content-Type: application/json" -d '{
"input": "LocalAI is very good!",
"model": "text-embedding-ada-002"
}' | jq "."
The following should be the typical trimmed embedding output:
{
"created": 1727016161,
"object": "list",
"id": "d35f6a77-7da1-455b-89ed-eb78abe5a940",
"model": "text-embedding-ada-002",
"data": [
{
"embedding": [
-0.008191858,
-0.09954127,
-0.016300818,
-0.012371115,
-0.027302064,
0.0045262217,
-0.042277347,
-0.02430437,
-0.04672008,
-0.024999944,
[... SNIP ...]
0.09827942,
0.045544963,
0.032365486,
-0.05366797,
-0.0005518062,
0.10040694,
0.0007584206,
0.029535804,
-0.078608364,
0.08886422
],
"index": 0,
"object": "embedding"
}
],
"usage": {
"prompt_tokens": 0,
"completion_tokens": 0,
"total_tokens": 0
}
}
Next, to try to send a user text to the Microsoft Phi-3 model for an embedding response, execute the following command:
$ curl -s http://192.168.1.25:8080/v1/embeddings -X POST -H "Content-Type: application/json" -d '{
"input": "LocalAI is very good!",
"model": "Phi-3-mini-4k-instruct-q4.gguf"
}' | jq "."
The following would be the typical output with no embeddings:
{
"created": 1727018558,
"object": "list",
"id": "d6529541-dfcc-4dc0-af32-0b41ffa941d7",
"model": "Phi-3-mini-4k-instruct-q4.gguf",
"data": [
{
"embedding": [],
"index": 0,
"object": "embedding"
}
],
"usage": {
"prompt_tokens": 0,
"completion_tokens": 0,
"total_tokens": 0
}
}
Hmm - that is interesting behavior; no embedding response from the Microsoft Phi-3 model.
One needs to ENABLE embedding for the Microsoft Phi-3 model by deploying the following model YAML file in the $HOME/.local_ai/models directory and restarting the LocalAI platform docker instance:
name: phi-3
context_size: 512
embeddings: true
parameters:
model: Phi-3-mini-4k-instruct-q4.gguf
temperature: 0.0
template:
chat: &template |-
Instruct: {{.Input}}
Output:
completion: *template
To retry sending the user text to the Microsoft Phi-3 model for an embedding response, execute the following command:
$ curl -s http://192.168.1.25:8080/v1/embeddings -X POST -H "Content-Type: application/json" -d '{
"input": "LocalAI is very good!",
"model": "phi-3"
}' | jq "."
The following would be the typical trimmed embedding output:
{
"created": 1727307803,
"object": "list",
"id": "959a068d-f030-488b-b337-247f78b87f4d",
"model": "phi-3",
"data": [
{
"embedding": [
-1.0195472,
-1.3165551,
-0.26669496,
0.4127312,
0.47328725,
0.3564262,
-1.5296685,
-1.0853969,
0.98751307,
0.19800761,
[... SNIP ...]
-1.12035,
-0.8108336,
-1.7172599,
0.6686336,
-1.0012463,
0.55254453,
-0.98265296,
1.0306809,
0.2582409,
0.8211594
],
"index": 0,
"object": "embedding"
}
],
"usage": {
"prompt_tokens": 0,
"completion_tokens": 0,
"total_tokens": 0
}
}
Moving on to the next task of text generation ...
To send a user prompt to the default gpt-4 LLM model for a response, execute the following command:
$ curl -s http://192.168.1.25:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "gpt-4",
"messages": [{"role": "user", "content": "Describe llm model using less than 50 words"}],
"temperature": 0.0
}' | jq
The following would be the typical output:
{
"created": 1727482599,
"object": "chat.completion",
"id": "15772965-367d-4bd6-ada3-c4fe41a390be",
"model": "gpt-4",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "The LLM (Large Language Model) is a deep learning-based neural network that predicts the probability of a sequence of words in a given context. It's trained on vast text data, enabling it to generate coherent sentences and understand natural language. LLMs are used in various NLP applications like language translation, text summarization, and chatbots."
}
}
],
"usage": {
"prompt_tokens": 19,
"completion_tokens": 71,
"total_tokens": 90
}
}
To retry sending the user prompt to the Microsoft Phi-3 LLM model for a response, execute the following command:
$ curl -s http://192.168.1.25:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "Phi-3-mini-4k-instruct-q4.gguf",
"messages": [{"role": "user", "content": "Describe llm model using less than 50 words"}],
"temperature": 0.0
}' | jq
The following would be the typical output:
{
"created": 1727050107,
"object": "chat.completion",
"id": "f13d028f-e015-4131-97e8-0af36d6e3921",
"model": "Phi-3-mini-4k-instruct-q4.gguf",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "<|end|><|assistant|> LLM models are large-scale neural networks trained on vast text corpora, enabling natural language understanding and generation.\n\n<|assistant|> LLMs, like GPT, analyze patterns in data to predict and generate human-like text.\n\n<|assistant|> LLMs are deep learning architectures that process and produce language, mimicking human linguistic capabilities.<|end|><|assistant|> Large Language Models (LLMs) are advanced AI systems that use deep neural networks to understand and generate human language, drawing from extensive datasets to improve accuracy and contextual relevance.<|end|><|endoftext|>"
}
}
],
"usage": {
"prompt_tokens": 13,
"completion_tokens": 121,
"total_tokens": 134
}
}
Moving on to the next task of text to audio generation ...
To send a sample text to the default tts-1 audio generation model and store the audio output to a file, execute the following command:
$ curl -s http://192.168.1.25:8080/tts -H "Content-Type: application/json" -d '{
"input": "LocalAI is very good!",
"model": "tts-1"
}' -o $HOME/Downloads/local_ai.wav
There will be output on the terminal and audio file will be saved as specified.
Here is the generated audio file:
Moving on to the final task of text to image generation ...
To send a sample text to the default stablediffusion image generation model and store the image output to a file in the directory $HOME/.local_ai/images, execute the following command:
$ curl -s http://192.168.1.25:8080/v1/images/generations -H "Content-Type: application/json" -d '{
"prompt": "a deer in a park with snow",
"size": "256x256"
}' | jq
The following would be the typical output:
{
"created": 1727024501,
"id": "1f44a571-a714-4b70-b3c7-3c4989a9d857",
"data": [
{
"embedding": null,
"index": 0,
"url": "http://192.168.1.25:8080/generated-images/b64297992501.png"
}
],
"usage": {
"prompt_tokens": 0,
"completion_tokens": 0,
"total_tokens": 0
}
}
The following is the generated image by the model:

Finally, shifting gears to demonstrate the various tasks using the OpenAI SDK ...
The following are the contents of the environment configuration file .env:
AUDIO_PATH='tts.wav' EMBEDDING_MODEL='phi-3' LLM_MODEL='gpt-4' API_KEY='polarsparc' BASE_URL='http://192.168.1.25:8080/v1/'
To load the environment configuration and initialize variables, execute the following code snippet:
from dotenv import load_dotenv, find_dotenv
import os
load_dotenv(find_dotenv())
audio_path = os.getenv('AUDIO_PATH')
embedding_model = os.getenv('EMBEDDING_MODEL')
llm_model = os.getenv('LLM_MODEL')
api_key = os.getenv('API_KEY')
base_url = os.getenv('BASE_URL')
There will be no output generated.
To get the embedding vector for a given input text from the LocalAI platform, execute the following code snippet:
from openai import OpenAI
client = OpenAI(
api_key=api_key,
base_url=base_url
)
text = 'LocalAI is great for local testing!'
response = client.embeddings.create(
input = [text],
model='phi-3',
)
print(response.data[0].embedding)
The following should be the typical trimmed output:
[-1.7110181, 0.7559086, -0.17279382, 0.5759084, 0.8554333, -0.04297254, -1.0151633, -1.1279765, 0.7601889, 1.069952, 0.15233377, -0.5367082, [... SNIP ...] 0.94074285, 1.0568386, 0.1046655, 0.3014798, 0.1539442, -0.58139473, -0.48626956, -2.0425005, 0.5001784, -0.5407203, -1.6669745, -0.9634145, 1.7683916, -1.1274788, -0.6037725, -0.83273834, 0.21806715, 0.69920886, 0.5833381]
To send a user prompt to the LLM model running on the LocalAI platform, execute the following code snippet:
messages = [{"role": "user", "content": "Describe llm model using less than 50 words"}]
response = client.chat.completions.create(
messages=messages,
model=llm_model,
stream=False,
)
print(response.choices[0].message.content)
The following should be the typical output:
The LLM (Large Language Model) is a deep learning-based algorithm that predicts and generates human-like text, often used in natural language processing tasks. It's trained on vast amounts of text data, learning patterns and relationships between words. The model can then produce coherent sentences or complete texts, given an input or context. LLMs have widespread use in applications like chatbots, language translation, and text generation.
To generate an audio output for the user text from the model running on the LocalAI platform and store the output audio to a file in the directory $HOME/.local_ai/audio, execute the following code snippet:
response = client.audio.speech.create( model='tts-1', voice='shimmer', input=text ) response.stream_to_file(audio_path)
There will be output on the terminal and audio file will be saved as specified.
Here is the generated audio file:
To generate an image corresponding to the user prompt from the model running on the LocalAI platform and store the output image to a file in the directory $HOME/.local_ai/images, execute the following code snippet:
response = client.images.generate( prompt='a cute snow leopard', size='512x512', ) print(response.data[0].url)
The following should be the typical output:
http://192.168.1.25:8080/generated-images/b641698569574.png
The following is the generated image by the model:

This concludes the various demonstrations on using the LocalAI platform as a local instance of OpenAI for development and testing !
References